Shengran Hu

I am Shengran Hu (胡圣然). I am a member of the founding team at ![]() Recursive and a Computer Science Ph.D. student at University of British Columbia, advised by Prof. Jeff Clune. Previously, I was a research scientist intern at Sakana AI.
Recursive and a Computer Science Ph.D. student at University of British Columbia, advised by Prof. Jeff Clune. Previously, I was a research scientist intern at Sakana AI.
I’m interested in how patterns and knowledge emerge from complex systems like natural evolution and scientific discovery. I study this by building open-ended, agentic AI systems that can accumulate complexity in language.
Email / Google Scholar / Github / Twitter
Selected Publications
(*denotes equal contribution †denotes equal advisory)
-
 Towards End-to-End Automation of AI ResearchNature, 2026
Towards End-to-End Automation of AI ResearchNature, 2026
-
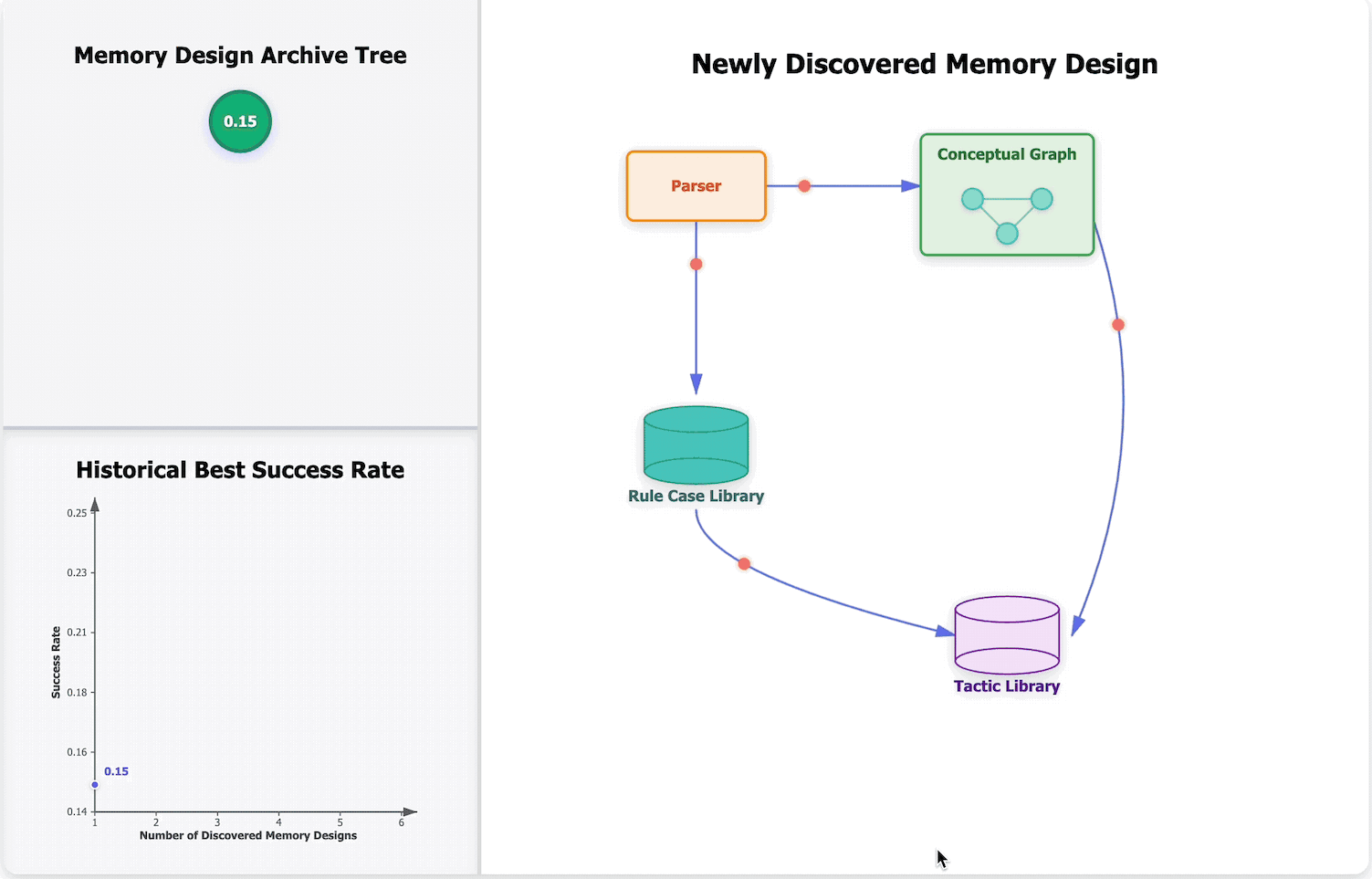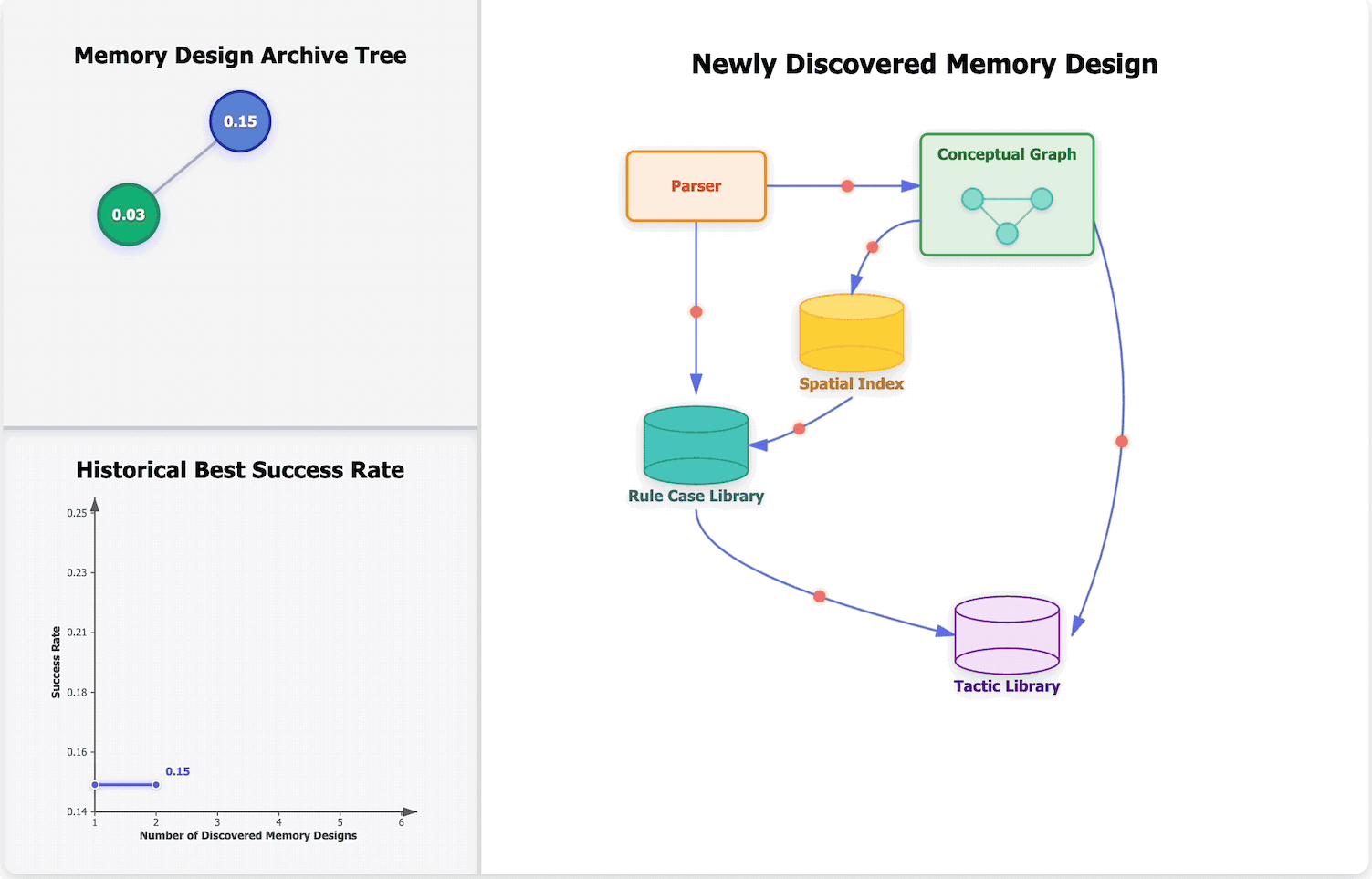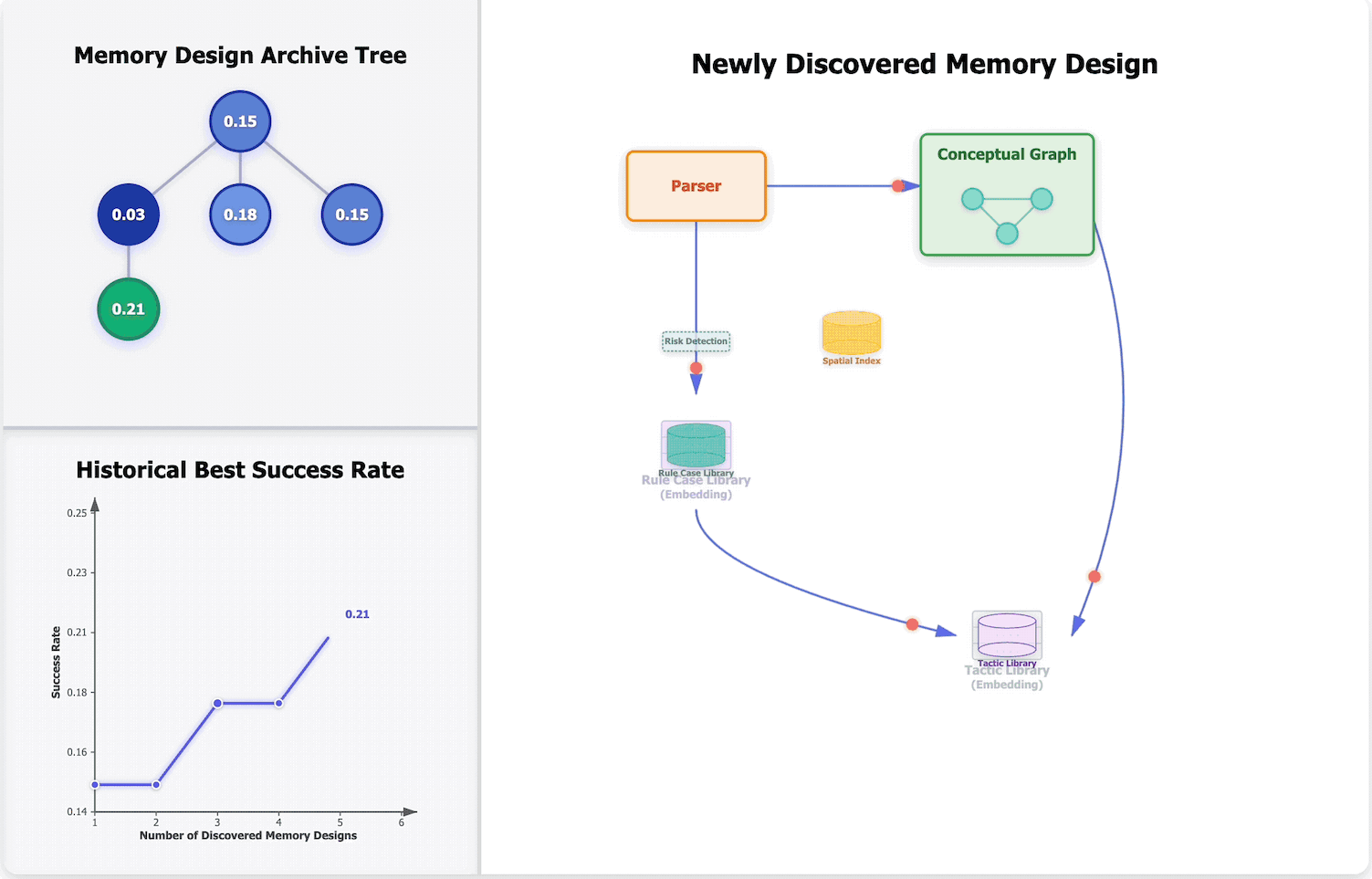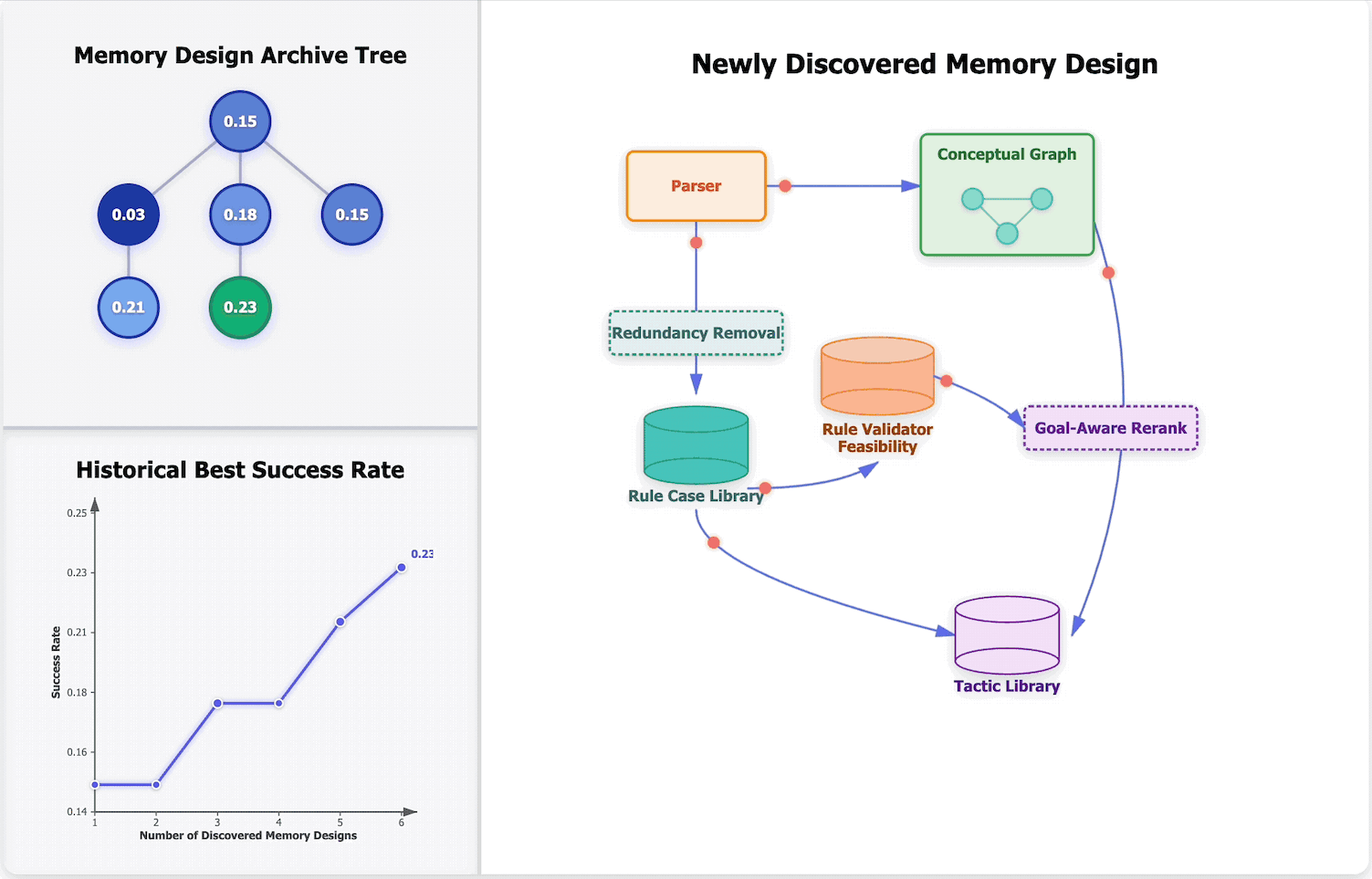 Learning to Continually Learn via Meta-learning Agentic Memory DesignsarXiv preprint arXiv:2602.07755, 2026🏆 Best Paper (ICLR 2026 MemAgent Workshop) and Outstanding Paper (ICLR 2026 RSI Workshop)
Learning to Continually Learn via Meta-learning Agentic Memory DesignsarXiv preprint arXiv:2602.07755, 2026🏆 Best Paper (ICLR 2026 MemAgent Workshop) and Outstanding Paper (ICLR 2026 RSI Workshop)
-
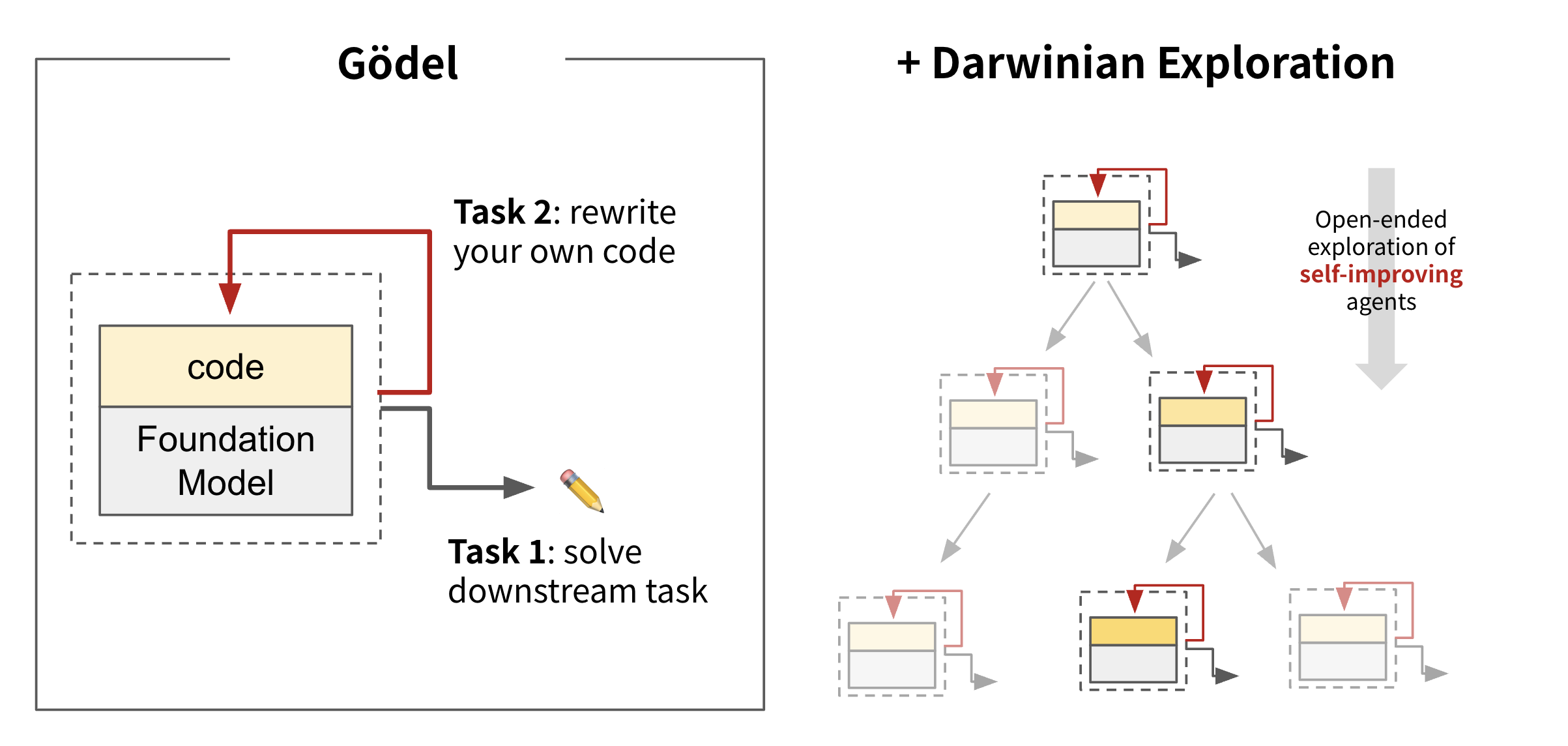 Darwin Gödel Machine: Open-Ended Evolution of Self-Improving AgentsInternational Conference on Learning Representations (ICLR), 2026
Darwin Gödel Machine: Open-Ended Evolution of Self-Improving AgentsInternational Conference on Learning Representations (ICLR), 2026
-
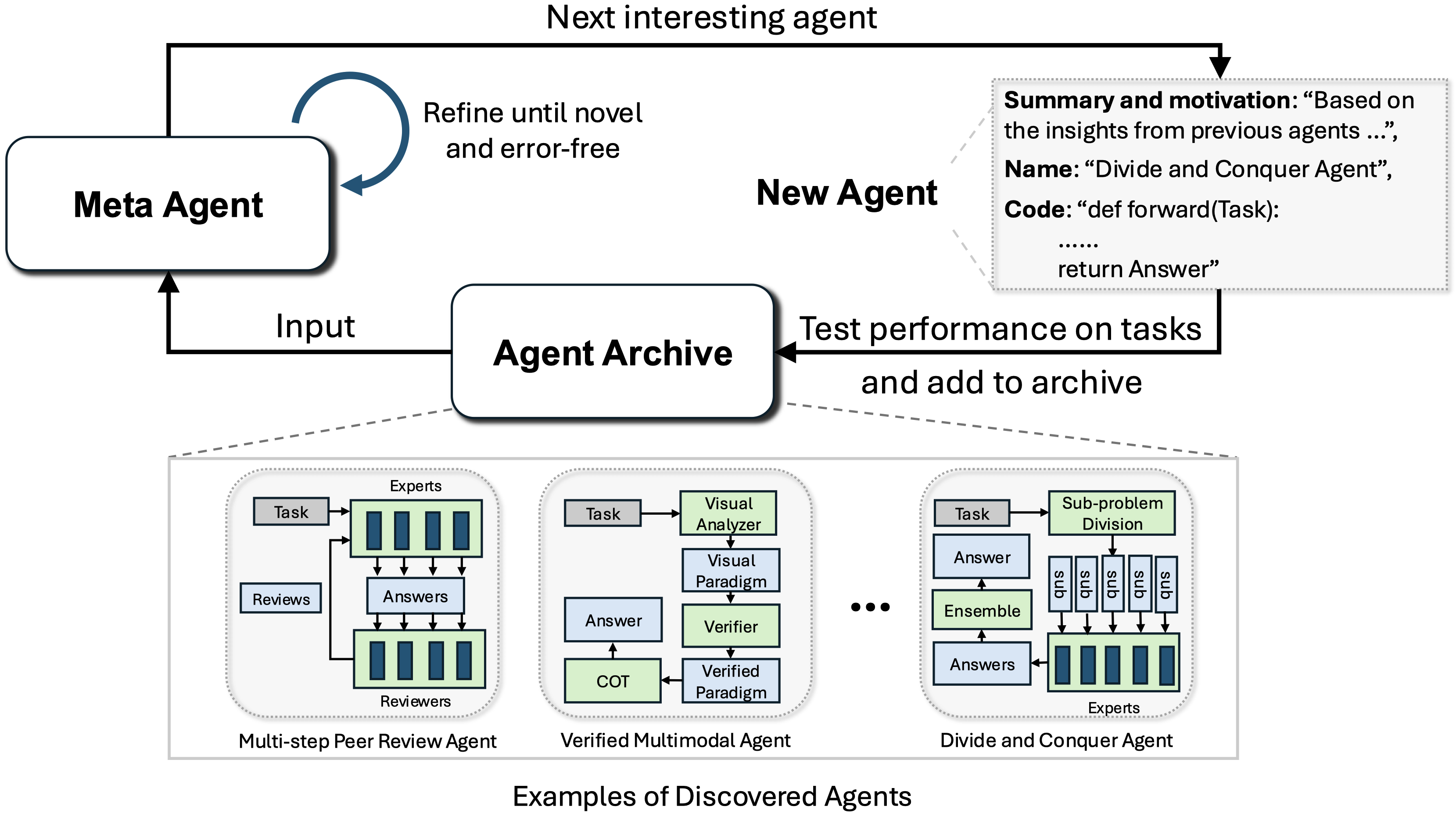 Automated Design of Agentic SystemsInternational Conference on Learning Representations (ICLR), 2025🏆 Outstanding Paper (NeurIPS 2024 Open-World Agent Workshop)
Automated Design of Agentic SystemsInternational Conference on Learning Representations (ICLR), 2025🏆 Outstanding Paper (NeurIPS 2024 Open-World Agent Workshop)
-
 Automated Capability Discovery via Foundation Model Self-ExplorationarXiv preprint arXiv:2502.07577, 2025
Automated Capability Discovery via Foundation Model Self-ExplorationarXiv preprint arXiv:2502.07577, 2025
-
 Thought Cloning: Learning to Think while Acting by Imitating Human ThinkingAdvances in Neural Information Processing Systems (NeurIPS), 2023Spotlight (top 3.1% in 12,343)
Thought Cloning: Learning to Think while Acting by Imitating Human ThinkingAdvances in Neural Information Processing Systems (NeurIPS), 2023Spotlight (top 3.1% in 12,343)













Selected Media Coverage















Selected Talks



